1. Dropout là gì, nó có ý nghĩa gì trong mạng neural network
Theo Wikipedia, thuật ngữ “dropout” đề cập đến việc bỏ qua các đơn vị (unit) (cả hai hidden unit và visible unit) trong mạng neural network.
Đang xem: Drop Out Trong Tiếng Tiếng Việt
Hiểu đơn giản là, trong mạng neural network, kỹ thuật dropout là việc chúng ta sẽ bỏ qua một vài unit trong suốt quá trình train trong mô hình, những unit bị bỏ qua được lựa chọn ngẫu nhiên. Ở đây, chúng ta hiểu “bỏ qua – ignoring” là unit đó sẽ không tham gia và đóng góp vào quá trình huấn luyện (lan truyền tiến và lan truyền ngược).
Về mặt kỹ thuật, tại mỗi giai đoạn huấn luyện, mỗi node có xác suất bị bỏ qua là 1-p và xác suất được chọn là p
2. Tạo sao chúng ta cần dropout
Giả sử rằng bạn hiểu hoàn toàn những gì đã nói ở phần 1, câu hỏi đặt ra là tại sao chúng ta cần đến dropout, tại sao chúng ta cần phải loại bỏ một vài các unit nào đó trong mạng neural network?
Câu trả lời cho câu hỏi này là để chống over-fitting
Khi chúng ta sử dụng full connected layer, các neural sẽ phụ thuộc “mạnh” lẫn nhau trong suốt quá trình huấn luyện, điều này làm giảm sức mạng cho mỗi neural và dẫn đến bị over-fitting tập train.
3. Dropout
Đọc đến đây, bạn đã có một khái niệm cơ bản về dropout và động lực – động cơ để chúng ta sử dụng nó. Nếu bạn chỉ muốn có cái nhìn tổng quan về dropout trong neural network, hai sections trên đã cung cấp đầy đủ thông tin cho bạn, bạn có thể dừng tại đây. Phần tiếp theo, chúng ta sẽ nói kỹ hơn về mặt kỹ thuật của dropout.
Trước đây, trong machine learning, người ta thường sử dụng regularization để ngăng chặn over-fititng. Regularization làm giảm over-fitting bằng cách thêm yếu tố “phạt” vào hàm độ lỗi (loss function). Bằng việc thêm vào điểm phạt này, mô hình được huấn luyện sẽ giúp các features weights giảm đi sự phụ thuộc lẫn nhau. Đối với những ai đã sử dụng Logistic Regression rồi thì sẽ không xa lạ với thuật ngữ phạt L1(Laplacian) và L2 (Gaussian).
Dropout là một kỹ thuật khác, một cách tiếp cận khác để regularization trong mạng neural netwoks.
Kỹ thuật dropout được thực hiện như sau:
Trong pha train: với mỗi hidden layer, với mỗi trainning sample, với mỗi lần lặp, chọn ngẫu nhiên p phần trăm số node và bỏ qua nó (bỏ qua luôn hàm kích hoạt cho các node bị bỏ qua).
Trong pha test: Sử dụng toàn bộ activations, nhưng giảm chúng với tỷ lệ p (do chúng ta bị miss p% hàm activation trong quá trình train).
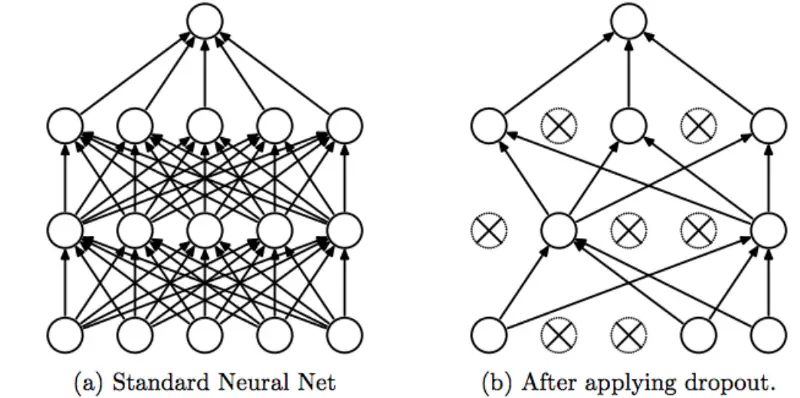
Mô tả về kiến trúc mạng có và không có dropout
4. Một số đặc điểm rút ra được khi huấn luyện nhiều mô hình khác nhau sử dụng dropout
Dropout ép mạng neural phải tìm ra nhiều robust features hơn, với đặc điểm là chúng phải hữu ích hơn, tốt hơn, ngon hơn khi kết hợp với nhiều neuron khác.
Xem thêm: Cổ Phiếu Phái Sinh Là Gì ? Kiến Thức Cần Biết Rủi Ro Gì Với Nhà Đầu Tư Mới
Dropout đòi hỏi phải gấp đôi quá trình huấn luyện để đạt được sự hội tụ. Tuy nhiên, thời gian huấn luyện cho mỗi epoch sẽ ít hơn.
Với H unit trong mô hình, mỗi unit đều có xác xuất bị bỏ qua hoặc được chọn, chúng ta sẽ có 2^H mô hình có thể có. Trong pha test, toàn bộ network được sử dụng và mỗi hàm activation được giảm đi với hệ số p.
5. Thực nghiệm trong keras
Những vấn đề nói ở trên chỉ là lý thuyết. Bây giờ chúng ta sẽ bắt tay vào làm thực tế. Để xem thử dropout hoạt động như thế nào, chúng ta sẽ xây dựng mô hình deep net sử dụng keras và sử dụng tập dữ liệu cifar-10. Mô hình chúng ta xây dựng có 3 hidden layer với kích thước lần lượt là 64, 128, 256 và 1 full connected layer có kích thước 512 và output layer có kích thước 10 (do mình có 10 lớp).
Chúng ta sử dụng hàm kích hoạt là ReLU trên các hidden layer và sử dụng hàm sigmoid trên output layer. Sử dụng hàm lỗi categorical cross-entropy.
Trong trường hợp mô hình có sử dụng dropout, chúng ta sẽ set dropout ở tất cả các layer và thay đổi tỷ lệ dropout nằm trong khoảng từ 0.0 đến 0.9 với bước nhảy là 0.1.
Mô hình setup với số epochs là 20. Bắt đầu xem nào.
Đầu tiên, chúng ta sẽ load một vài thư viện cần thiết
import numpy as npimport osimport kerasfrom keras.datasets import cifar10from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activation, Flattenfrom keras.layers import Convolution2D, MaxPooling2Dfrom keras.optimizers import SGDfrom keras.utils import np_utilsfrom keras.preprocessing.image import ImageDataGeneratorimport matplotlib.pyplot as pltfrom pylab import rcParamsrcParams<"figure.figsize"> = 20, 20from keras.datasets import cifar10(X_train, y_train), (X_test, y_test) = cifar10.load_data()print(“Training data:”)print(“Number of examples: “, X_train.shape<0>)print(“Number of channels:”,X_train.shape<3>) print(“Image size:”,X_train.shape<1>, X_train.shape<2>, X_train.shape<3>)print(“Test data:”)print(“Number of examples:”, X_test.shape<0>)print(“Number of channels:”, X_test.shape<3>)print(“Image size:”,X_test.shape<1>, X_test.shape<2>, X_test.shape<3>)Kết quả
Training data:Number of examples: 50000Number of channels: 3Image size: 32 32 3Test data:Number of examples: 10000Number of channels: 3Image size: 32 32 3Chúng ta có 50000 hình train, và 10000 hình test. Mỗi hình là một ảnh RGB có kích thước 33x32x3 pixel.

dataset cifar 10
Tiếp theo, chúng ta sẽ chuẩn hoá dữ liệu. Đây là 1 bước quan trọng trước khi huấn luyện mô hình
# In<3>:Specify Training ParametersbatchSize = 512 #– Training Batch Sizenum_classes = 10 #– Number of classes in CIFAR-10 datasetnum_epochs = 100 #– Number of epochs for training learningRate= 0.001 #– Learning rate for the networklr_weight_decay = 0.95 #– Learning weight decay. Reduce the learn rate by 0.95 after epochimg_rows, img_cols = 32, 32 #– input image dimensionsY_train = np_utils.to_categorical(y_train, num_classes)Y_test = np_utils.to_categorical(y_test, num_classes)batchSize = 512 #– Training Batch Sizenum_classes = 10 #– Number of classes in CIFAR-10 datasetnum_epochs = 100 #– Number of epochs for training learningRate= 0.001 #– Learning rate for the networklr_weight_decay = 0.95 #– Learning weight decay. Reduce the learn rate by 0.95 after epochimg_rows, img_cols = 32, 32 #– input image dimensionsY_train = np_utils.to_categorical(y_train, num_classes)Y_test = np_utils.to_categorical(y_test, num_classes)# In<4>:VGGnet-10from keras.layers import Conv2Dimport copyresult = {}y = {}loss = <>acc = <>dropouts = <0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9>for dropout in dropouts: print(“Dropout: “, (dropout)) model = Sequential() #– layer 1 model.add(Conv2D(64, (3, 3), border_mode=”valid”, input_shape=( img_rows, img_cols,3))) model.add(Dropout(dropout)) model.add(Conv2D(64, (3, 3))) model.add(Dropout(dropout)) model.add(Activation(“relu”)) model.add(MaxPooling2D(pool_size=(2, 2))) ##–layer 2 model.add(Conv2D(128, (3, 3))) model.add(Dropout(dropout)) model.add(Activation(“relu”)) model.add(MaxPooling2D(pool_size=(2, 2))) ##–layer 3 model.add(Conv2D(256, (3, 3))) model.add(Dropout(dropout)) model.add(Activation(“relu”)) model.add(MaxPooling2D(pool_size=(2, 2))) ##– layer 4 model.add(Flatten()) model.add(Dense(512)) model.add(Activation(“relu”)) #– layer 5 model.add(Dense(num_classes)) #– loss model.add(Activation(“softmax”)) sgd = SGD(lr=learningRate, decay = lr_weight_decay) model.compile(loss=”categorical_crossentropy”, optimizer=”sgd”, metrics=<"accuracy">) model_cce = model.fit(X_train, Y_train, batch_size=batchSize, epochs=20, verbose=1, shuffle=True, validation_data=(X_test, Y_test)) score = model.evaluate(X_test, Y_test, verbose=0) y
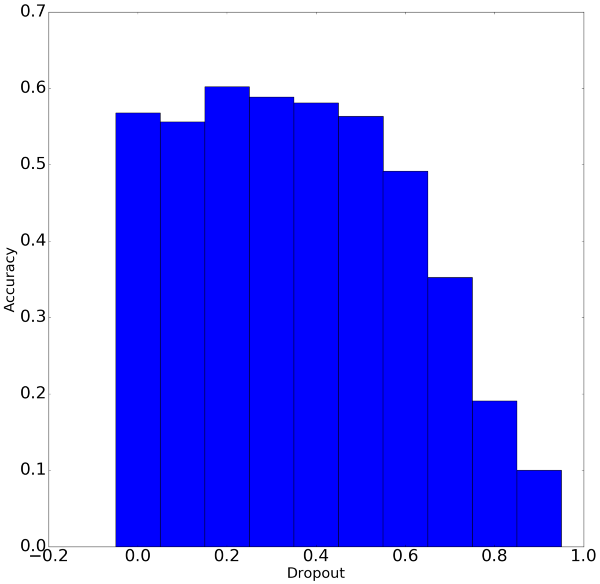
Kết quả
Nhìn hình kết quả ở trên, chúng ta có một số kết luận nhỏ như sau:
Giá trị dropout tốt nhất là 0.2, khoảng dropout cho giá trị chấp nhận được là nằm trong đoạn từ 0 đến 0.5. Nếu dropout lớn hơn 0.5 thì kết quả hàm huấn luyện trả về khá tệ.
Xem thêm: Cloramphenicol 250Mg : Liều Dùng & Lưu Ý, Hướng Dẫn Sử Dụng, Tác Dụng Phụ
Giá trị độ chính xác còn khá thấp => 20 epochs là chưa đủ, cần huấn luyện nhiều hơn nữa.